
SITUS RESMI
BERITA TEKNOLOGI - DARI LUWU TIMUR
Dunia kecerdasan buatan (AI) baru saja menyaksikan lompatan besar dalam efisiensi komputasi. Pada akhir Maret 2026, Google DeepMind resmi memperkenalkan TurboQuant, sebuah teknik kompresi memori mutakhir yang dirancang untuk mengatasi masalah terbesar dalam operasional Large Language Models (LLM): pembengkakan memori pada konteks panjang. Teknologi ini dijadwalkan untuk dipresentasikan secara formal di konferensi ICLR 2026, namun dampaknya sudah mulai terasa di pasar global.
Dunia kecerdasan buatan (AI) baru saja menyaksikan lompatan besar dalam efisiensi komputasi. Pada akhir Maret 2026, Google DeepMind resmi memperkenalkan TurboQuant, sebuah teknik kompresi memori mutakhir yang dirancang untuk mengatasi masalah terbesar dalam operasional Large Language Models (LLM): pembengkakan memori pada konteks panjang.
Teknologi ini dijadwalkan untuk dipresentasikan secara formal di konferensi ICLR 2026, namun dampaknya sudah mulai terasa di pasar global.
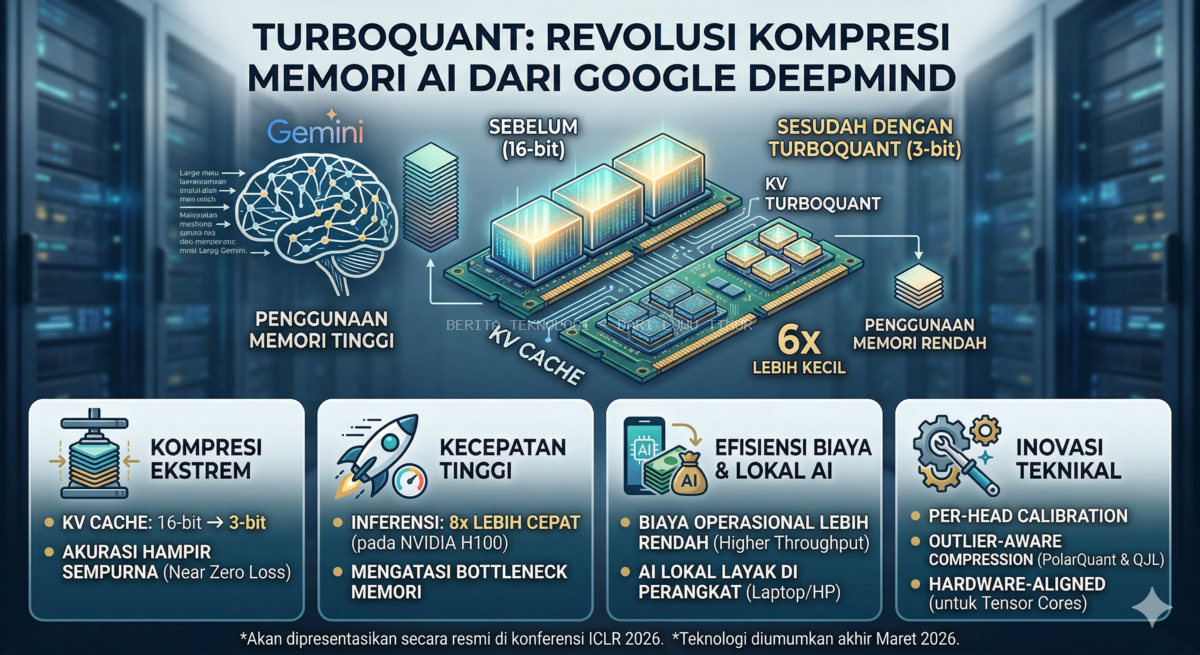
Saat Anda berinteraksi dengan AI seperti Gemini dengan dokumen setebal ratusan halaman (konteks panjang), GPU tidak hanya menyimpan bobot model, tetapi juga menyimpan Key-Value (KV) cache.
Dalam skenario penggunaan 1 juta+ token, KV cache sering kali memakan ruang memori yang jauh lebih besar daripada model itu sendiri. Inilah yang selama ini menjadi penghambat utama (bottleneck) yang membuat biaya operasional AI menjadi mahal dan aksesnya lambat.
TurboQuant adalah solusi kompresi ekstrem yang mampu mengecilkan ukuran KV cache dari presisi standar 16-bit menjadi hanya 3-bit.
Penghematan Memori 6x Lipat: Memungkinkan GPU menangani data enam kali lebih banyak dalam ruang yang sama.
Kecepatan Inferensi 8x Lebih Cepat: Diuji pada GPU NVIDIA H100, proses pembacaan data menjadi jauh lebih instan.
Hampir Tanpa Penurunan Akurasi (Near-Zero Loss): Meskipun dikompresi secara agresif, kecerdasan model dalam memahami tugas kompleks tetap setara dengan presisi penuh.
TurboQuant tidak sekadar mengecilkan angka; ia menggunakan pendekatan cerdas yang disebut hardware-aligned compression:
Per-head Calibration: Alih-alih menerapkan satu aturan kompresi untuk seluruh model, TurboQuant melakukan kalibrasi mandiri pada setiap attention head.
Outlier-aware Compression: Sistem secara cerdas mengidentifikasi nilai-nilai "penting" (outliers) dan menyimpannya secara terpisah, sementara nilai lainnya dikompresi secara agresif.
PolarQuant & QJL: Menggabungkan koordinat polar untuk menangkap makna semantik dan teknik Quantized Johnson-Lindenstrauss (QJL) untuk memperbaiki kesalahan sekecil apa pun saat data dibuka kembali.
Munculnya TurboQuant membawa efek domino yang signifikan di berbagai sektor:
Pengumuman ini sempat mengejutkan pasar modal. Saham produsen memori raksasa seperti Micron, SK Hynix, dan Samsung mengalami penurunan karena investor khawatir efisiensi perangkat lunak ini akan mengurangi ketergantungan industri pada High-Bandwidth Memory (HBM) yang mahal.
Dengan kebutuhan memori yang turun drastis, menjalankan LLM tingkat lanjut di laptop atau ponsel (AI lokal) kini menjadi sangat memungkinkan tanpa perlu bergantung pada server cloud.
Teknologi ini akan menjadi tulang punggung bagi evolusi Gemini dan layanan pencarian semantik Google, memungkinkan respons yang lebih cepat bagi jutaan pengguna secara bersamaan dengan biaya operasional yang lebih rendah.
TurboQuant membuktikan bahwa masa depan AI tidak hanya bergantung pada "otot" (perangkat keras yang lebih besar), tetapi juga pada "otak" (optimasi perangkat lunak yang lebih cerdas). Dengan mampu mengompresi data hingga 3-bit tanpa mengorbankan kecerdasan, Google DeepMind telah membuka pintu bagi era AI yang lebih murah, lebih cepat, dan tersedia bagi siapa saja.
Catatan: Detail teknis lengkap mengenai riset ini akan dipublikasikan secara resmi pada ajang ICLR 2026.












